Anomaly Detection with AWS CloudWatch
CloudWatch has become an integral part of managing any AWS eco-system. Whether you are on traditional EC2 type services, containers or modern serverless, you can use CloudWatch to provide insights into capacity planning, and help diagnose issues with services and your applications. From humble beginnings1 in 2009 where you were able to monitor basic metrics of EC2 instances and it was optional, to today with the latest anomaly detection support.
You are able to push custom metrics to CloudWatch either from your application or from the operating system using tools such as the CloudWatch Agent, push logs for analysis, storing for compliance purposes or as an interim step into another log analysis system or SIEM. CloudWatch also provides events that can trigger a workflow. CloudWatch has definitely become a very powerful in the AWS builders toolbox.
Next Generation MSP
As an AWS certified next generation MSP, we have been providing next generation monitoring capabilities to customers for a few years. Sometimes, this has been through the use of alternative third-party commercial or open-source solutions. These solutions have had various levels of success over the years, but generally have never felt like they had that tight integration I was looking for. Anomaly and outlier detection has been a crucial part of this requirement, and to have this now available directly in CloudWatch is awesome.
With this announcement, it means that we'll be able to bring this powerful monitoring approach to more customers than we have before due to the pay-for-what-you-consume approach. We can apply anomaly detection to just the metrics that make sense for each customer for thean utterly ridiculous price of USD 30c per month.
Example
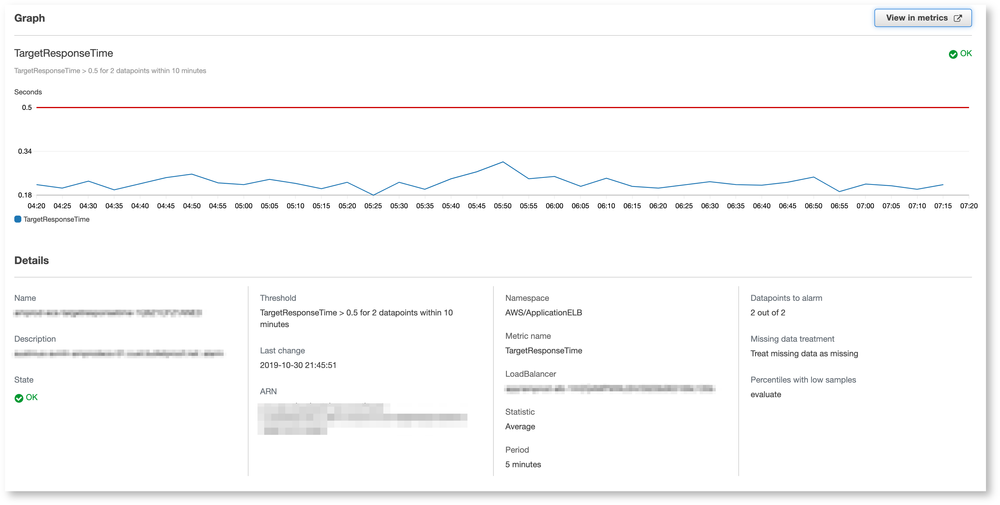
Threshold Based
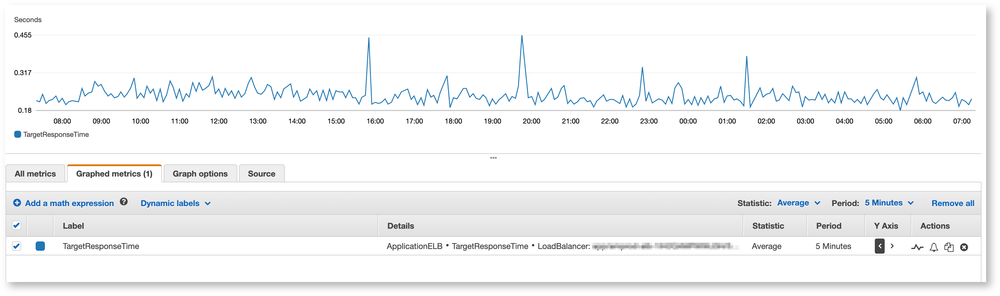
Let's take a look at an example.
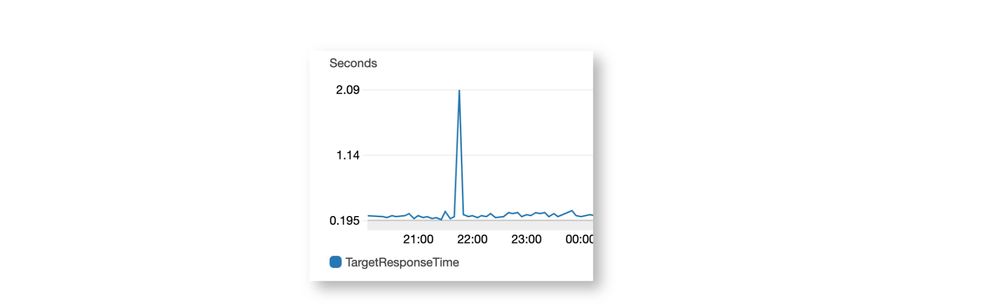
I have a container based CMS running for a customer. This frontend stack is a traditional three-tier approach. One application load-balancer, N+1 auto-scaling containers, and Multi-Node PostgreSQL Aurora. In this example we are interested in how fast the application containers are responding. For this, we measure the TargetResponseTime on the application load-balancer.