Delta lake
Delta Lake is an open-source storage layer that brings reliability to data lakes. This article delves into the world of Delta Lake, its capabilities, and its transformative role in data management.
Understanding Delta Lake
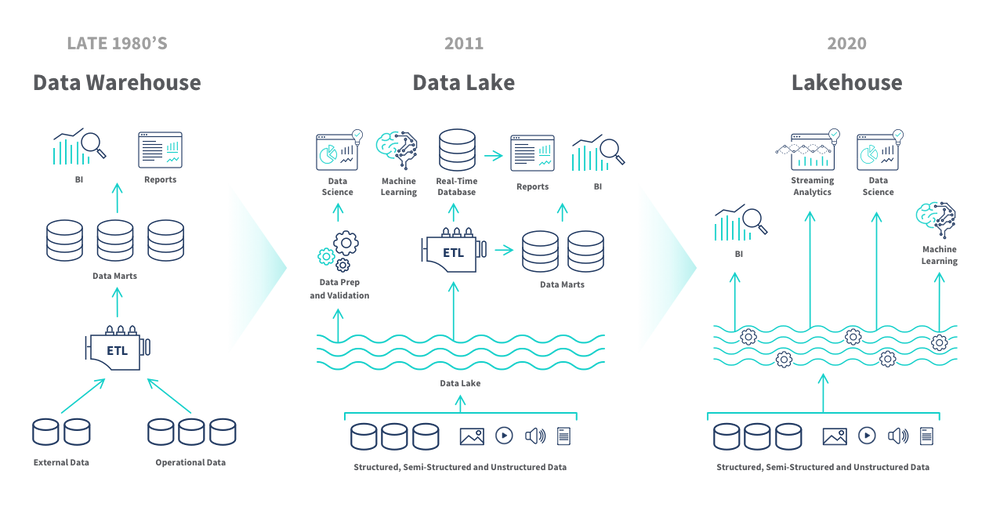
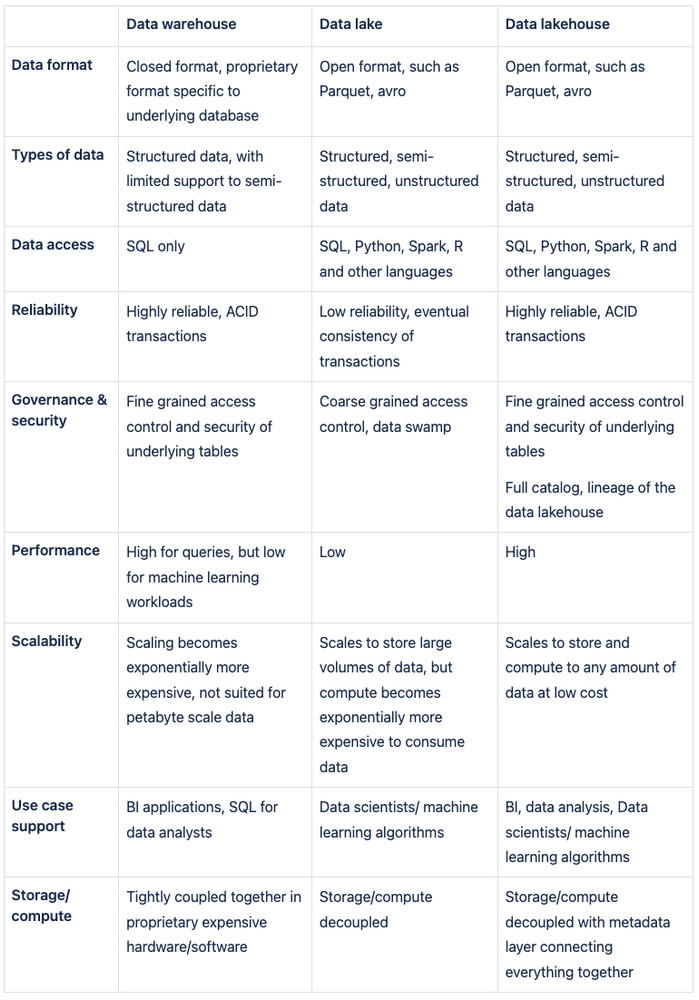
Delta Lake is an innovative technology that provides a robust storage layer to data lakes. While data lakes are known for their ability to store vast amounts of raw, heterogeneous data, they often lack structure and reliability. Delta Lake addresses these issues, offering ACID transaction capabilities, schema enforcement, and version control - features typically associated with structured data warehouses.
ACID Transactions: Delta Lake brings ACID transactions to data lakes. ACID (Atomicity, Consistency, Isolation, Durability) transactions ensure data integrity during operations such as inserts, updates, and deletes. This is crucial when multiple users are concurrently reading and writing data, as it prevents conflicts and ensures consistent views of the data.
Schema Enforcement and Evolution: Delta Lake enforces a schema upon write operations, preventing the insertion of corrupt or inconsistent data. Additionally, it allows for schema evolution, meaning the schema can be modified as data evolves, providing a high degree of flexibility.
Data Versioning: Delta Lake also offers data versioning capabilities, storing a transaction log that keeps track of all changes made to the data. This means it is possible to roll back to previous versions of the data if necessary, making it a powerful tool for audit trails and data recovery.
Delta Lake in the Databricks Ecosystem
Within the Databricks ecosystem, Delta Lake plays a pivotal role. It forms the foundation of the Databricks Lakehouse platform, which combines the strengths of data lakes and data warehouses. The result is a single, unified architecture that supports diverse data workloads while maintaining high performance and reliability.
Delta Lake also integrates seamlessly with Apache Spark, the popular open-source, distributed computing system. This integration allows for fast, parallel processing of large datasets - a key requirement for big data analytics. Furthermore, Delta Lake is fully compatible with Spark APIs, which means existing Spark workloads can run on Delta Lake without any modifications.
Delta Lake supports a variety of data science and machine learning workflows. By ensuring data reliability and consistency, it allows data scientists to build robust, reproducible machine learning models.
Governance of data lake house with Databricks Unity catalogue
Data governance is a crucial aspect of modern data architectures, particularly as businesses shift towards lakehouse models. The Databricks Unity Catalog is a key offering in this regard, providing a unified, managed catalog service that simplifies data governance in lakehouse architectures.
Understanding Databricks Unity Catalog
The Databricks Unity Catalog is a centralised metadata service designed to improve data governance across Databricks workspaces. It provides an integrated and consistent view of your data assets, regardless of their location, thereby improving data discovery, accessibility, and management.
The Unity Catalog integrates with Databricks' other key offerings, including Delta Lake and SQL Analytics, providing a unified layer of metadata across all data and analytics workloads. This means that regardless of where your data is stored or how it's being used, you can manage it all from a single, centralized platform.
Benefits of Databricks Unity Catalog for Data Lakehouses
Data lakehouses, which combine the best aspects of data lakes and data warehouses, need robust data governance mechanisms to ensure data quality, security, and compliance. The Unity Catalog plays a vital role in this regard, offering several key benefits:
- Improved Data Discovery and Accessibility: By providing a unified view of data assets across various sources and workspaces, the Unity Catalog makes it easier to discover and access relevant data. This improves productivity and empowers users to derive more insights from their data
- Enhanced Data Governance: The Unity Catalog supports schema enforcement and evolution, ensuring data consistency and integrity. It also provides fine-grained access control, allowing you to manage who can access what data, thereby enhancing data security
- Streamlined Data Management: By centralising metadata management, the Unity Catalog streamlines data management tasks. This simplifies the process of tracking data lineage, managing data lifecycle, and implementing data retention policies
- Seamless Integration: The Unity Catalog seamlessly integrates with Databricks' other offerings, making it easy to manage and govern data across all workloads. Whether you're running batch processing jobs with Delta Lake, performing interactive analysis with SQL Analytics, or building machine learning models, you can do it all with a unified, governed data layer
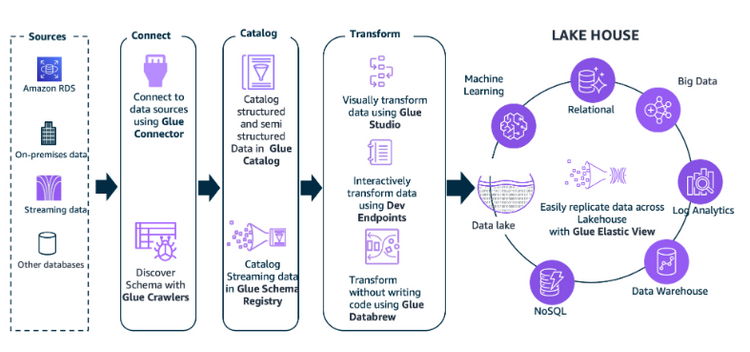
Lakehouse Approach on AWS
The concept of Lakehouse is not limited to Databricks. Lakehouse can be implemented on public cloud providers such as AWS. Below are some of the key AWS services and how they are used in implementation of Lakehouse.